Back Home
Overview
The DARPA shredder challenge was a project to kick start the
development of software techniques to reconstruct shredded documents
recovered from a warzone. This is DARPA's archive.
The internet wayback machine may do better. On a whim I
decided to give the Shredder Challenge a solo shot. Ultimately the
team "All Your Shreds Are Belong To Us" won the $50k prize.
The objective was to go from scanned input files like this (but
higher resolution)

To this: (not my results)

Approach
The top level approach was the same as assembling a puzzle: In
stages assemble groups of pieces into ever larger and larger
chunks. I assumed each puzzle would take a slightly different
approach, therefore the code developed would exist mostly as a
library. The solution for each puzzle would be computed by
running a sequence of programs, customized for that puzzle, each
program reading input files from the previous stage(s) and writing
its results into its own filesystem directory. I integrated
human guidance by having software present its 'best' guesses for a
particular fit, then have the human select the best/proper fits.
Finding shreds
The first step was to break the input files into individual puzzle
shreds. First I used ImageMagick
to scale and sharpen the input file. The sharpened image file
was then loaded and processed by custom code. In that code I
specified a grid. From each grid point a flood fill would search
outward for all pixels colors that where deemed to be a shred (i.e.
not magenta), then to progress several pixels beyond this capturing
some background color pixels. The found piece was written to a
rectangular image file with a background filled with cyan for
distinctiveness.
This is an example piece. I saved all image files as .ppm files for
ease of programming (and lossless handling).

To prevent finding the same piece multiple times, the removed pixels
were 'colored' as the source background before starting the shred
search again from another grid location.
Machine Fitting
I chose to perform a exhaustive brute force fitting technique, where
piece 'A' would be rotated and displaced over piece 'B' in
relatively small pixel and angle increments. The fit would was
scored heuristically. In the example above many yellow pixels
from 'A' covering yellow pixels in 'B' would be deemed to be a bad
fit, but a fit where only yellow pixels overlap magenta pixels would
be good. The best solutions from the first fitting group would
then be then go though an optimization process where even smaller
rotations and pixels displacements would be tried. The highest
scoring solutions from the optimized fits would be retained and
sorted.
I decided early on (probably mistakenly) that I should not do any
sort of initial/pre rotation of the pieces for alignment because it
looked like this would not help solving later puzzles. This
made the range of fits that needed to be tried massive and the
overall fitting computation very expensive.
To 'solve' the computation problem, I coded up a distributed
computing system where a small workgroup of desktop pc's would
perform the fitting operation on a pair of pieces and report the
best solutions.
Human Guidance
After the Machine Fitting process, the resulting database would be
loaded into the XGass program that would allow a piece to be
presented and selected. By hitting the space bar (or 'p' for
previous fit) a computer machine fit could be tried and displayed in
the overall puzzle. If that optional fit was deemed 'good' by
the human, it could be 'added' to the display, then its position and
angle further tweaked interactively.
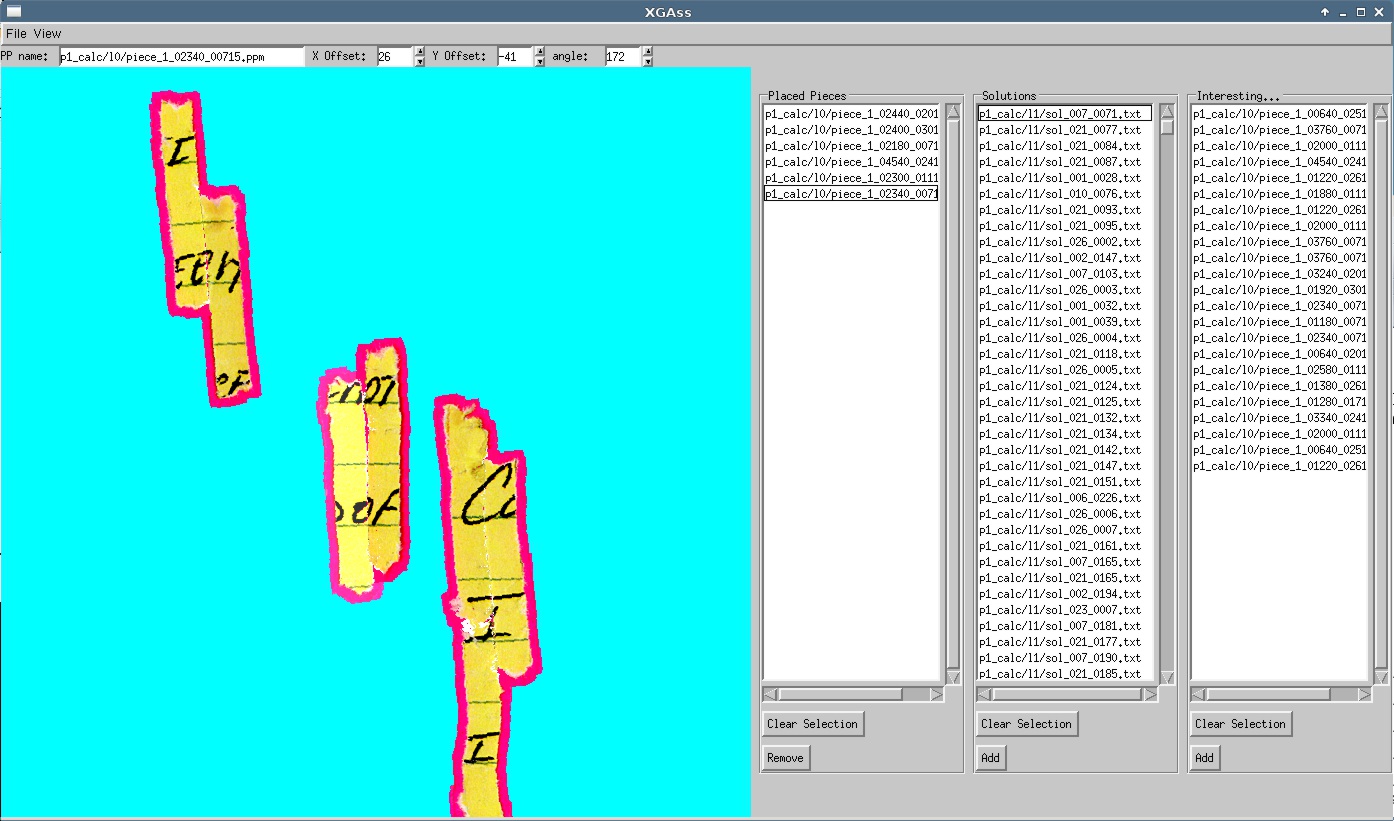
In this case the center piece with the slightly lighter magenta
border has been selected and the piece to the right is being test
fit. XGass was implemented quick and dirty with libGx for the UI and
libImg for software image and transparency rendering.
Project Log / Timeline
These are basically my raw notes. ~100 hrs total over ~2 weeks
~12hrs first day able to find individual paper pieces from sample
image and break into individual files
~7hrs next day. splitting code into multiple programs. 1st is
yesterday's code that finds pieces and outputs them as individual
files. now also output a piece directory file
2nd code reads the directory file and loads the fragments. started
on a fitter algorithm and successfully implemented the rotate
function (to rotate fragment images) as part of the fitter.
~9hrs 3rd day. made fitter generate reasonable results between pairs
of pieces. worked on performance improvement. dropped single pass of
fitter between two pieces on problem #1 from ~70min to ~8min through
inlining & other optimizations.
~5hrs 4th day. got most of distributed computing implementation
done.
~6.5 hrs 5th day. got distributed computing working. modified fitter
to use course grid to select 'interesting' cases then use higher
resolution on those few. experimented with 1/2 and 1/4 resolution on
p1.
~4hrs 6th day. small code cleanups. found hw problem in cluster
machine. simplified cluster startup and monitoring wrt this problem.
recognized need in problem 1 to retain higher resolution.
worked/thought about how to assemble groups of pieces and how to
organize the code and data to do this.
~5hrs 7th day. worked toward idea to operate in an interactive
'tree' mode. each step finds the best larger pieces from the
previous step's data. the output from each step can be hand guided
as an input to the next step. brought more 'cluster' machines
online. wrote p2.cc p3.cc and most of p4.cc
~8hrs 8th day. worked on fitter to try an judge the quality of the
fit between pieces by considering not only the distance matched in
terms of shape, but also the color match across the fit of the
writing. first implementation was horribly expensive. looked for
reason why and discovered it was just horribly expensive. No easy
tuning can be done.
~4hrs 9th day did some more work to organize output in tree
structure. worked to find best solutions in a range of pieces
connecting and disconnecting from remote servers. not good fit
results
~7hrs 10th day. re-approaching problem 1 scaled to 1/4 to reduce
computational time. not able to get good fits as 1st choice so
tweaked score calculations. sort of fixed bugs in reconnecting to
remote machines (race condition left). loosened interesting fit
criteria because I thought I was discarding interesting pieces (then
went back and tightened up criteria when fits did not improve).
finally found typo in Scoring code and added algorithmic enhancement
to get back to ok/sane results. sorting pieces to allow limiting
search between those that have a lot of 'other' colors. (trying to
reduce n^2)
~10.5hrs 11th day must improve fitter. now if color in one
piece and no related color on other piece a penalty is applied.
l1-4 increased contrast of paper.
l1-5 added new pixel type (paper core)
l1-6 more properly configured paper color thresholds via
false_color -> this is why more advanced fitting (50% overlap)
was giving s*** results
should rerun with 99% sharpness
must pre-compute pixel type and store in alpha to speed all
routines in Fitter.
should add cost for background pixels in fitting window.
must implement fit solution assembler.
~3hrs 12th day worked on gui of interactive placement tool that
leverages fit data. (xgass) continued letting l1-6 run to completion
~14hrs 13th day implemented huge chunk of interactive tool xgass
continued letting l1-6 run to completion
~8hrs 14th day. added features to gass & fixed bugs l1-6
finished running 2810:17 min of compute time for each machine
then worked to implement ideas above to speed up fitter
(really just storing pixel type in alpha).
alpha change yielded 2x speedup reults in l1-1 noted typo bug
in fitter
fixed bug. also increased desired # of results per piece
pair. to 100 from 5 in l1-2. i can spare the ram?
results in l1-2 -> no huge difference in
results -> some change in order.
made fitter change to HardFit adding a cost for gaps between
pieces. results in l1-3. not much better & judged some
really bad ones
as better than some really good ones. some
of best fits judged worst?!
increased window size to 10 pixels. results in l1-4 *** much
better *** but many similar solutions perhaps discarding other good
ones.
??? hrs 15th day. implemented discarding all but best solutions
'close' to one another. should let more varied interesting solutions
through fitter.
Evaluation
After the end of the timeline I let the code crank on puzzle
1. The main problem with my approach was computational
time. I began looking at going to the amazon cloud, or even
buying the same $ of surplus machines from craigslist. At this point
I was disappointed with my filtered results, and looking at the cost
of computing/electricity, I decided to drop my effort.
Postscript
Now, several years later and writing up these results, I got my
software up and running on a much faster machine than I had at the
time (I was on some obsolete athlonMPs - now a single Xeon
W3565). I ran this code at 2x resolution shreds I than I used
originally (>4x slower) and crunching though puzzle 1 took more
than a month on a single workstation, yielding the results in the
XGass screenshot above. The fitter code needs tweaking as it
gives lots of obviously bad results mixed in with some pretty good
guesses. I think my big mistake at the time was not
pre-filtering the pieces to make them at least all vertical if not
looking for the characteristic notch left by the shredder and
orienting all the pieces in a given direction. This would have
dropped the Fitter effort by an order of magnitude and would have
worked much better overall. I also think this sort of
calculation is perfect for a GPU, but at the time I was grossly
unfamiliar with that technology.
Competition Files
and Winners
Winning Teams
Submissions
Honorable Mentions